Two of the most widely discussed tools for handling large volumes of data are Apache Spark and MapReduce. Both serve as frameworks for processing big data, but they approach tasks in fundamentally different ways. While they share the common goal of managing massive datasets, Spark and MapReduce each have distinct advantages and limitations.
In this article, we'll examine the features of both, analyze their advantages and disadvantages, and help you understand the main differences that can determine your choice of tool for your data processing requirements.
What is Spark?
Apache Spark is an open-source distributed computing framework for processing big data at high speed. In contrast to batch-processing systems, Spark runs in memory, where it caches intermediate data in RAM, resulting in a considerable reduction in processing time. Spark can process both batch and real-time data, which makes it a general-purpose choice for big data applications today.
Spark comes with a higher-level API that makes programming easy by supporting numerous languages like Java, Python, Scala, and R. Spark also includes the ability to run advanced analytics operations like machine learning using MLlib, graph analysis using GraphX, and querying using SQL via Spark SQL. This is made possible by Spark's versatility, which makes it the go-to for data engineers and scientists who are required to undertake intricate operations on large datasets rapidly and effectively.
Pros of Spark
One of Spark's major advantages is that it is very fast because it does not require writing intermediate results to disk while processing data in memory. This brings enormous performance gains, especially for iterative machine learning and interactive data analysis. Spark is also easy to use, with APIs in several programming languages, which makes it simpler for developers to use without requiring them to learn new frameworks.
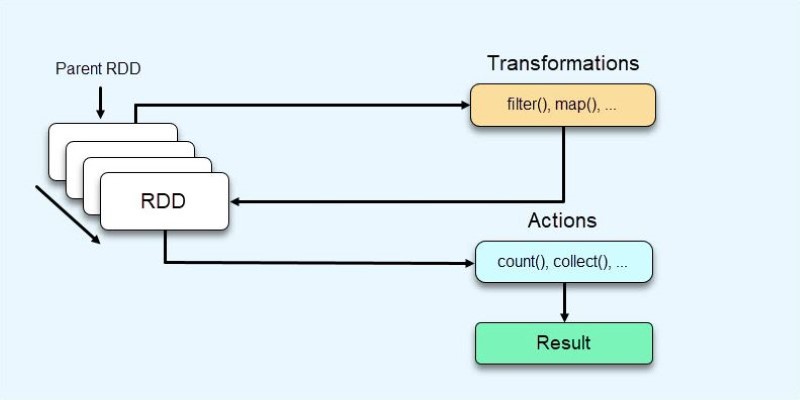
Its single engine enables batch, streaming, and machine learning, eliminating workflow complexity. Also, Spark offers fault tolerance via Resilient Distributed Datasets (RDDs), making data computable again from the original dataset should nodes fail.
Cons of Spark
Spark, though possessing numerous advantages, has some disadvantages. One of the main problems is memory usage. As Spark operates in memory, it needs to consume a lot of RAM, which might be costly for big-scale operations. When data doesn't fit into memory, Spark's performance suffers. It might be challenging to optimize Spark to a specific workload.
Although the high-level APIs make development easier, they might hide the underlying complexities and make it more difficult to optimize for performance. Debugging can also be challenging in distributed environments, particularly when handling failures across large clusters, complicating issue resolution.
What is MapReduce?
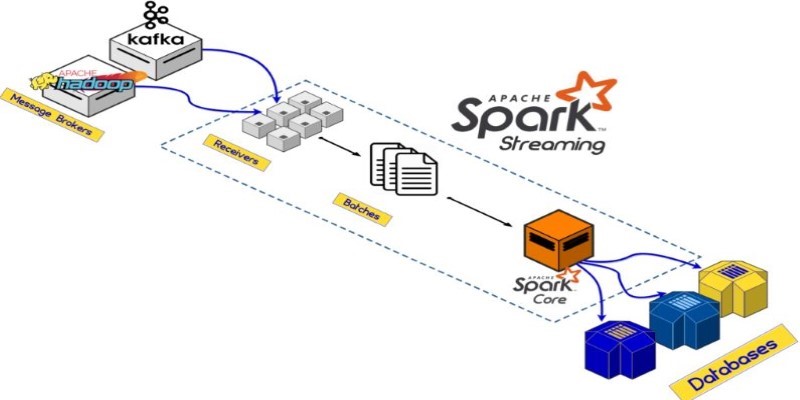
MapReduce, developed by Google and popularized by Apache Hadoop, is a programming model used to process large datasets in parallel across distributed clusters. The MapReduce model consists of two main functions: the "Map" function, which processes input data and generates intermediate key-value pairs, and the "Reduce" function, which aggregates those key-value pairs to produce the final output.
MapReduce is known for its scalability and ability to process vast amounts of data across many nodes in a cluster. It is primarily used for batch processing and is well-suited for applications that involve simple transformations or aggregations over large datasets. Many organizations rely on MapReduce for traditional big data tasks, such as log analysis, data warehousing, and batch processing.
Pros of MapReduce
MapReduce is known for its simplicity, making it easy to understand, especially for those with a background in functional programming. It is highly scalable and capable of distributing tasks across many machines, which is ideal for processing massive datasets. Another benefit is its integration with the Hadoop ecosystem.
As a core component of Hadoop, MapReduce leverages the scalability, reliability, and fault tolerance provided by Hadoop's Distributed File System (HDFS), enabling parallel data processing. Additionally, MapReduce has been extensively used in production environments for many years, making it a reliable and battle-tested tool for large-scale data processing.
Cons of MapReduce
Despite its scalability and reliability, MapReduce has notable drawbacks. One significant issue is its speed, as it relies on disk I/O for intermediate data storage, which can slow down processing, particularly in iterative tasks. This is where Spark often outperforms MapReduce, as Spark processes data in memory.

Another limitation is the complexity of programming. While the basic model is simple, handling complex algorithms or multi-stage processes can become cumbersome. MapReduce also struggles with iterative machine learning tasks, as each iteration requires a full pass through the dataset, making it inefficient for those specific workloads.
Key Differences: Spark vs. MapReduce
The primary difference between Spark and MapReduce lies in how they process data. Spark uses in-memory processing, which allows it to work much faster than MapReduce, especially for iterative tasks. MapReduce, on the other hand, writes intermediate data to disk, leading to slower performance.
Another key difference is the level of complexity. Spark’s high-level APIs and unified engine for batch, streaming, and machine learning tasks make it more versatile and easier to use than MapReduce, which is typically limited to batch processing and is more complex to program.
Fault tolerance is another area where Spark and MapReduce differ. While both frameworks provide fault tolerance, Spark’s use of RDDs enables it to recompute lost data from the original dataset, making it more resilient. MapReduce relies on Hadoop’s HDFS for fault tolerance, but it can be slower to recover from failures due to its disk-based storage model.
Conclusion
Both Spark and MapReduce have their strengths and limitations, making them suitable for different use cases. Spark excels in speed, flexibility, and ease of use, especially for iterative and real-time data processing. However, it requires significant memory resources and can be challenging to optimize for certain tasks. On the other hand, MapReduce is reliable, simple, and well-integrated with the Hadoop ecosystem, but it suffers from slower performance and is less efficient for iterative operations. Choosing between Spark and MapReduce depends on the specific requirements of your big data processing needs, such as speed, scalability, and complexity.