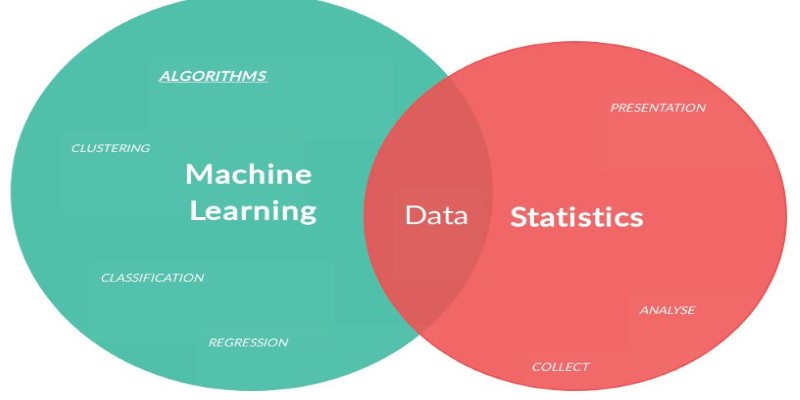
Data fuels decision-making, but not all analytical approaches are the same. While statistical Learning and Machine Learning are often used interchangeably, they follow different principles and serve distinct purposes. While both analyze patterns and make predictions, Statistical Learning leans on mathematical models and assumptions, whereas Machine Learning thrives on adaptability, automation, and scalability.
Knowing the difference isn't just academic—it's essential for selecting the right tool for the right problem. Whether you're dealing with structured datasets or complex, unstructured information, understanding these two fields can elevate your data-driven decisions. Let's break down their key differences and why they truly matter today.
What is Statistical Learning?
Statistical Learning is a branch of classical statistics with the objective of making models of relationships between variables and forecasting the outcomes. It is based on firmly established methods such as linear regression and logistic regression, which assume some conditions, e.g., normality or linearity in data. They are applied in many areas of study, including healthcare, economics, and social sciences, where databases are structured and relationships between variables are known.
One of Statistical Learning's greatest strengths is its readability. The models are transparent, and it is straightforward to see how various factors are affecting an outcome. For example, a linear regression model clearly defines how each predictor influences the dependent variable, allowing users to establish faith in the model's predictions.
What is Machine Learning?
Machine Learning is more adaptable in its approach. Rather than models with fixed structures, it applies algorithms that learn directly from the data, looking for patterns and making more accurate predictions as it goes along. Methods like decision trees, support vector machines, and deep learning are well suited to deal with enormous, complex data sets that don't meet standard statistical assumptions.

Although Machine Learning is capable of greater accuracy, particularly with bigger data sets, its models may not be as transparent. Numerous operate as "black boxes," and it is tricky to follow how they arrive at their conclusions. In spite of this, Machine Learning is critical in situations in which predictive capacity and scalability matter more than transparency.
Key Differences Between Statistical Learning and Machine Learning
While Statistical Learning and Machine Learning share a common goal of analyzing and predicting outcomes from data, they differ in several fundamental ways:
Theoretical Foundation:
Statistical Learning relies on statistical theory and predefined assumptions about data distribution. It's ideal for situations where data is well-defined, allowing for clear relationships between variables. In contrast, Machine Learning is more data-driven, not requiring assumptions about data.
It excels in handling complex, unstructured, or large datasets where traditional statistical methods might struggle. This flexibility allows Machine Learning to adapt and uncover hidden patterns in vast, complex datasets without needing predefined models.
Interpretability of Models:
Statistical Learning is known for its interpretability. Models like linear regression provide clear insights into how changes in predictors affect the outcome. This transparency makes it easier to explain results and build trust. On the other hand, Machine Learning models, especially deep learning, are often "black boxes."
While they deliver high accuracy, they lack transparency, making it challenging to understand how predictions are made. This can be problematic in fields requiring clear explanations of decision-making.
Data Requirements:
Statistical Learning works best with smaller datasets and simpler models, helping to uncover relationships without needing large volumes of data. It is ideal for situations where the dataset is limited, but understanding the underlying distribution is crucial. Machine Learning, on the other hand, excels with large datasets and unstructured data.
It can identify complex patterns and adapt over time, making it particularly useful when dealing with vast amounts of information. As data grows, Machine Learning’s ability to refine and improve predictions becomes essential for accuracy.
Model Complexity:
Statistical Learning employs simpler models, such as linear regression and logistic regression, which make clear assumptions and are easier to interpret. These models are well-suited for smaller datasets or problems with straightforward relationships between variables.
In contrast, Machine Learning utilizes more complex algorithms, such as neural networks and random forests, which can capture intricate patterns in large datasets. While these models tend to offer better accuracy, especially with high-dimensional data, they are harder to interpret, making them less transparent compared to Statistical Learning models.
Applications:
Statistical Learning is commonly applied in fields like economics, healthcare, and social sciences, where datasets are typically smaller, and the relationships between variables are well understood. It is particularly useful in situations where interpretability is essential. Machine Learning, however, is widely used in industries such as finance, e-commerce, and artificial intelligence.
It shines in applications like image recognition, fraud detection, and natural language processing, where large, complex datasets require advanced models to detect patterns and make accurate predictions in high-dimensional and unstructured data.
Focus on Generalization vs. Overfitting:
Statistical Learning prioritizes building models that generalize well to new, unseen data. It does so by minimizing overfitting and striking a balance between bias and variance. Regularization techniques help maintain model simplicity and prevent the model from capturing noise in the data. On the other hand, Machine Learning, especially deep learning, can be prone to overfitting due to the complexity of the models. To prevent this, techniques like dropout, early stopping, and cross-validation are employed to improve generalization, ensuring the model performs well on data it hasn't seen before.
Conclusion
The choice between Statistical Learning and Machine Learning depends on your specific needs and data. Statistical Learning excels with smaller datasets and interpretable models, making it ideal for fields where relationships between variables are well-understood. Machine Learning, on the other hand, is better suited for large, complex datasets, offering powerful predictions even when the underlying patterns are unknown. Both approaches have their strengths, and understanding when to use each can help you make more informed decisions in data analysis and modeling.